mirror of
https://github.com/LBRYFoundation/lbry.com.git
synced 2025-08-23 09:37:26 +00:00
fix images, titles, notion link
This commit is contained in:
parent
3e843327a8
commit
eb752f2f45
1 changed files with 7 additions and 9 deletions
|
|
@ -5,11 +5,9 @@ date: '2019-03-26 15:00:00'
|
|||
cover: 'database2.jpg'
|
||||
category: technical
|
||||
---
|
||||
|
||||
# The claim trie memory reduction
|
||||
Here follows a little writeup on some work that we have done to make the data structure in LBRYcrd less naive (and less RAM-hungry). We anticipate that it will ship in a LBRYcrd release in late spring.
|
||||
|
||||
## Section 1: the requirements
|
||||
## Section 1: The Requirements
|
||||
|
||||
LBRY is a collection of names to bids. You might outline the data like so:
|
||||
|
||||
|
|
@ -44,7 +42,7 @@ It's decided then: we're going to move to a custom container with a tree structu
|
|||
|
||||
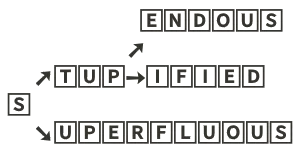
With this kind of structure, I can walk from the root node to the leaf node for any search in O(len(name)) time. I can keep a set of nodes that need their hashes updated as I go. It works okay, but now consider the general inefficiencies of this approach. Example keys: superfluous, stupendous, and stupified. How does that look?
|
||||
|
||||

|
||||
|
||||
|
||||
In other words, we're now using 25 nodes to hold three data points. All but two of those nodes have one or no child. 22 of the 25 nodes have an empty data member. This is RAM intensive and very wasteful.
|
||||
|
||||
|
|
@ -58,11 +56,11 @@ Over the years there have been many proposals to improve this structure. I'm goi
|
|||
|
||||
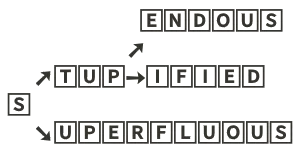
It ends up that idea #1 makes all the difference. You have to combine the nodes as much as possible. That turns the above trie into 5 nodes down from 25 becoming:
|
||||
|
||||

|
||||
|
||||
|
||||
## Section 2: the experiments
|
||||
## Section 2: The Experiments
|
||||
|
||||
[ Timed experiments for 1 million insertions of random data [a-zA-Z0-9]{1, 60}](https://www.notion.so/adecf55e97fb4c8080e5288bb44cd65d)
|
||||
[ Timed experiments for 1 million insertions of random data [a-zA-Z0-9]{1, 60}](https://www.notion.so/lbry/adecf55e97fb4c8080e5288bb44cd65d?v=187bbb545577449489d12bc87a1892bb)
|
||||
|
||||
A few notes about the table:
|
||||
|
||||
|
|
@ -78,7 +76,7 @@ We also experimented with a memory-mapped backing allocator. Namely: `boost::int
|
|||
|
||||
We experimented with using [LevelDB](https://github.com/google/leveldb) as the backing store for a custom trie. This has an interesting advantage in that we can keep trie history forever; we can index by hash as well as by name. It could be handy for querying the trie data from a snapshot of ancient days. We had trouble making this performant, though. It's at least an order of magnitude slower; it's not in the same league as the options in the chart. And for the in-RAM trie, rolling back just a few frames for a recent historical snapshot is usually not a big deal. LevelDB has a nice LRU cache feature. We saw that it used about 830MB of RAM with 100MB of LRU configured (for our test of 1M insertions). Whenever we run out of RAM again, this approach may again come into play.
|
||||
|
||||
## Section 3: how it works
|
||||
## Section 3: How it Works
|
||||
|
||||
A trie is made of nodes. We'll start with a simple definition for that:
|
||||
|
||||
|
|
@ -99,7 +97,7 @@ An illustration of `lower_bound`, assuming `set = std::set<std::string> { "B", "
|
|||
|
||||
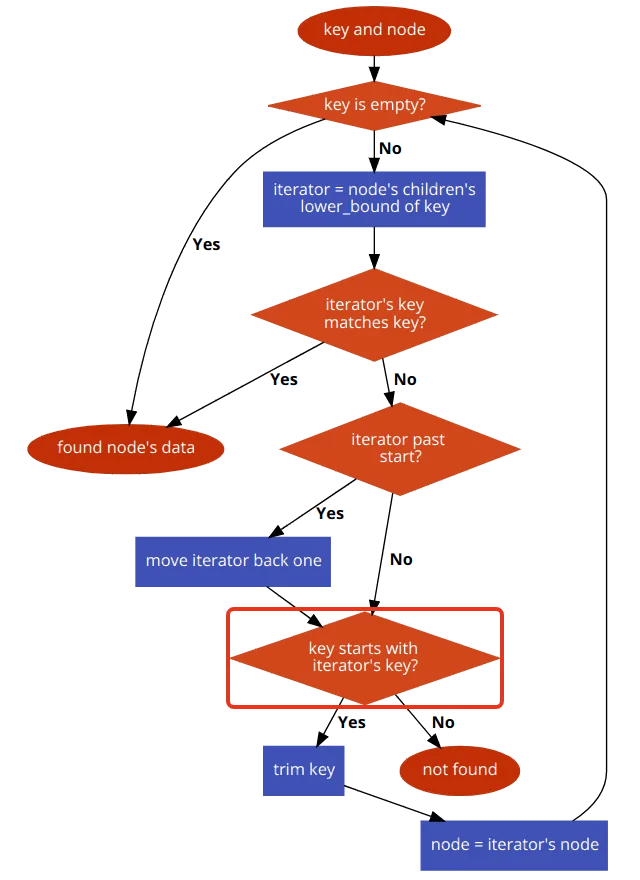
The general find algorithm:
|
||||
|
||||

|
||||
|
||||
|
||||
The general find algorithm in pseudo-code:
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Reference in a new issue